Natural Language Processing in the Detection of Fraud in Invoices of the City of São Paulo (part 2)

1. Methodology
The studies to solve the problem of this study began in 2019. On the occasion, the Fiscal Intelligence Unit had a machine and a visual tool with 2 GB RAM memory. The processing time was one week.
The current solution represents an evolution. It was developed in a configurable environment suitable for Big Data problems. The Jupyter development platform (Jupyter, 2015) was used and use was made of the Hadoop system. Programming routines were developed in Sqoop and Python languages to store, prepare data, and model texts with NLP. The environment was configured with 20 GB RAM memory. Advantages included the ability to distribute data processing and storage and develop flexible code.
The databases used were tables from the NFS-e of the Municipal Finance Secretariat of Sao Paulo from 2019 to 2022. The steps of the solution follow the flowchart in Figure 1. The following steps were performed:
- Import invoices from the highest aliquot code into the ADO Hadoop system.
- Apply Spark to process text from memo services:
- -Normalize lowercase terms.
- -Remove blank spaces.
- -Remove special characters, punctuation marks, accentuation, and stop words.
- -Radicalization and lemmatization.
- Create a table with the obtained words and their TF-IDF.
- Select invoices from the lower aliquot code that contain the most frequent terms from the higher aliquot code obtained in item 4. As most frequent terms, the 100 terms with the highest TF-IDF value were considered.
Figure 1: Flow chart of the solution steps
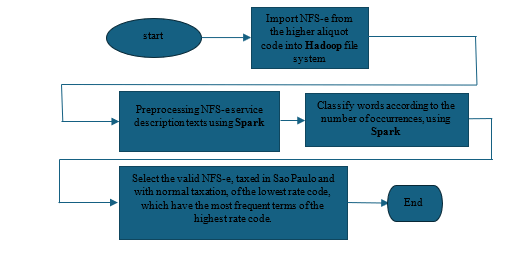
-
- -Import NFS-e from the higher aliquot code into Hadoop file system
- -Preprocessing NFS-e service description texts using Spark
- -Classify words according to the number of occurrences using Spark
- -Select the valid NFS-e taxed in Sao Paulo and with normal taxation of the lowest rate code which have the most frequent terms of the highest rat code
2. Results and Discussion
The tax operations issued resulting from the application of the methodology of this work were analyzed. An increasing trend was observed from 2019 to 2022, the period in which the methodology was applied. There was a total of 27 transactions conducted, 23 closed and 4 in progress, covering 27 companies as shown in Graph 1.
Graph 1 – Control operations issued
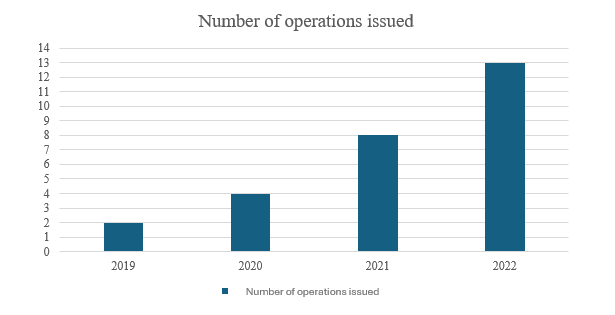
Source: Prepared by the authors (2024).
The figures for infringement notifications are shown in Graph 2, with 72% of the total amount of notifications paid. According to Graph 3, 249 invoices were issued. When evaluating the percentage share of tax assessments in company turnover, the percentage reaches 65%.
Graph 2 – Values of infringement notices
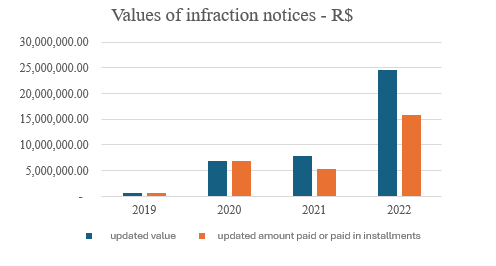
Source: prepared by the authors (2024).
Gráfico 3 – Cantidad de avisos de infracción
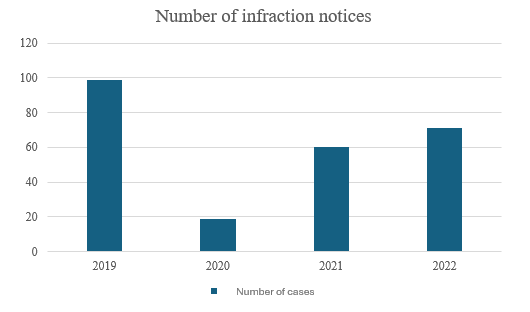
Source: Prepared by the authors (2024).
In terms of the volume of invoices analyzed, a total of 38,727,247 invoices were analyzed. This analysis was broken down into two groups: one group of invoices with a higher aliquot and one group of invoices with a lower aliquot. Graph 4 shows the annual evolution of these figures.
Graph 4 – Number of invoices analyzed
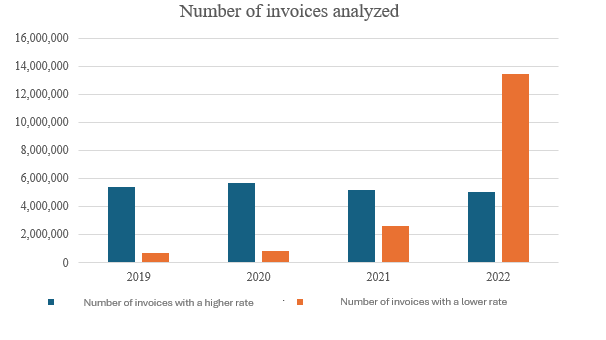
Source: Prepared by the authors (2024).
The evolution of the Services Tax (ISS) paid by taxpayers was analyzed going back to 2015 to measure the effect of the methodology. Increasing values were observed with a peak in 2019, the year in which the methodology began to be used, as shown in Graph 5. Analyzing the period from 2015 to 2018 before applying the methodology, the average ISS paid was R$7,732,552.89. In the period from 2019 to 2022, the average value was R$11,422,897.19, representing a 48% increase in revenue.
Graph 5 – ISS paid
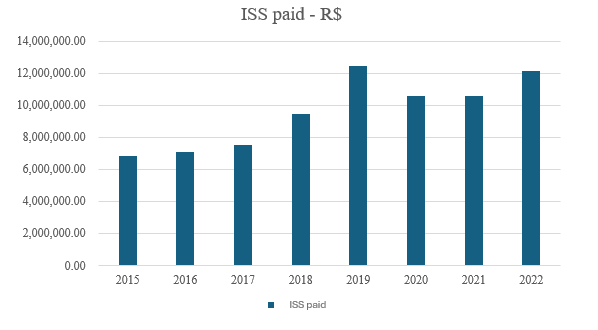
Source: prepared by the authors (2024).
- Conclusions
In the area of public administration, AI can improve audits. There is a large volume of taxpayers and invoices whose manual analysis requires extensive work. Some taxpayers benefit from this difficulty in defrauding the NFS-e. As a result, there is a demand for solutions that automate the analysis of large volumes of data, speeding up decisions and making tax actions more assertive, which increases tax revenues. The related works are based on solutions dependent on manual work based on unrepresentative data sets. No work was found with the aim of detecting fraud due to aliquot misuse and based on the study of the frequency of NFS-e terms. In this work, NLP techniques were applied to texts of descriptions of 38,727,247 NFS-e of the São Paulo Prefecture in the period 2019 to 2022. The most frequent terms used to detail services taxed at higher rates were discovered but are being applied to NFS-e with a lower rate service code. The discovery of these terms made it possible to select taxpayers issuing fraudulent NFS-e, allowing audit actions to be programmed efficiently. This resulted in a greater assertiveness of control actions reaching 72% of payment in the infraction notices. A large volume of NFS-e was analyzed, and an increasing payment of ISS was verified in the period under analysis. NLP adoption and Big Data infrastructure have accelerated fraud discovery and boosted revenue. In future work, we propose to apply Machine Learning techniques (MITCHELL 1997) to the data obtained with NLP with a view to classifying NFS-e. Thus, control actions may generate more promising results than those of this work in terms of efficiency of verification operations, assertiveness of infringement notices, and increase in tax collection.
References
JUPYTER. Project Jupyter Documentation. Internet page. Available at https://docs.jupyter.org/en/latest/. Accessed on 09/02/2024. Developed in 2015.
MITCHELL T. M. Machine Learning. Nueva York 1997.
6,493 total views, 5 views today