Navegando en los datos ŌĆ£In NaturaŌĆØ

En el a├▒o 2000 fui contratado para llevar a cabo una consultor├Ła en un ├ōrgano P├║blico del Estado de Brasil, con la misi├│n de desarrollar productos para el ├ürea de Fiscalizaci├│n.
En aquella ├®poca una empresa de gran porte en el ├Īrea de software estaba desarrollando hac├Ła m├Īs de dos a├▒os, un Almac├®n de Datos para atender al Departamento de Fiscalizaci├│n y no se vislumbraba resultado alguno dentro de los l├Łmites de tiempo del proyecto.
Al analizar la documentaci├│n generada, constatamos que esta era apenas una documentaci├│n de intenciones siguiendo los modelos de la metodolog├Ła de la empresa y que reflejaba una especificaci├│n hecha por los usuarios, careciendo, as├Ł de mayores detalles t├®cnicos necesarios para la consecuci├│n del proyecto.
Dada la urgencia de los resultados, tomamos entonces otro enfoque considerando las siguientes premisas en cuanto a los datos requeridos para el proyecto:
En cuanto a los requerimientos necesarios para atender el ├Īrea consideramos que:
Propusimos entonces la siguiente soluci├│n:
El sistema act├║a con refinamientos sucesivos: Una investigaci├│n est├Ī compuesta de Elementos, como resultado de selecciones de atributos de un Tema. La inclusi├│n de nuevos atributos genera un nuevo conjunto que est├Ī contenido en el conjunto inicial, y as├Ł sucesivamente. En cualquier momento la investigaci├│n puede ser conservada por ya ser el resultado final, o para ser usada en otras investigaciones, ya sea para la recuperaci├│n o presentaci├│n de los datos.
A esta altura algunos lectores deben estar preocupados con la propuesta de acceso a los datos operacionales. La idea es usar las mismas estructuras, por ello en el caso analizado se usaron los mismos datos operacionales, debido al n├║mero limitado de usuarios que accesan el sistema y principalmente por una implementaci├│n del sistema conocida como Conjunto de Base. El Conjunto de Base es uno que se usa como referencia, de partida; o sea, que cualquier conjunto resultante siempre pertenece o est├Ī contenido en el Conjunto de Base.
Entrar en un Tema como Recaudaci├│n, Notas Fiscales Electr├│nicas, entre otros, sin un Conjunto de Base puede ser demorado para un sistema que sea repetitivo. Por eso, si el Conjunto de Base tiene algunos millares de Elementos y el banco de datos est├Ī bien configurado no hay mayores problemas.
Ejemplo:
Consideramos la existencia del Tema Catastro, el Tema Actividades Econ├│micas de los Contribuyentes, el Tema de Recaudaci├│n y el Tema de Importaciones:
El objetivo es la obtenci├│n de Contribuyentes identificados por el CNPJ de una franja de capital social, de un conjunto de Actividades Econ├│micas y que originaron m├Īs de un determinado valor y pagaron menos de un monto de impuesto en un per├Łodo de referencia dado;
En 4 tenemos el resultado deseado, una lista de CNPJ que corresponde al ejemplo. El usuario podr├Ła efectuar cualesquiera de las otras operaciones en los conjuntos obteniendo los conjuntos conforme a su necesidad, o igualmente seguir otra estrategia de navegaci├│n. Adem├Īs, si la cantidad de elementos no responde a los requisitos, el usuario puede ajustar el capital social o usar otros c├│digos de actividad econ├│mica, u otros par├Īmetros para incluir o eliminar contribuyentes del conjunto seleccionado.
Una vez obtenido el conjunto de elementos adecuado, salvo en un historial de investigaciones, este conjunto puede ser utilizado en cualquier momento para la extracci├│n de datos de cualesquiera temas configurados en el sistema, o servir de control para la generaci├│n de casos y la emisi├│n de ├│rdenes de servicio para los equipos de fiscalizaci├│n, o servir de conjuntos para participar en otras operaciones con nuevos conjuntos.
Este sistema estuvo disponible en su versi├│n inicial en 6 meses y el resultado fue tan satisfactorio que pas├│ a ser utilizado por la Asesor├Ła del Secretario de Ingresos para la extracci├│n de informaci├│n gerencial del ├Īrea de recaudaci├│n, entre otras.
En la versi├│n inicial implantada este sistema era conocido como ŌĆ£PLAFIS ŌĆōPlaneamiento de Fiscalizaci├│n ŌĆō M├│dulo GerencialŌĆØ. Posteriormente, fue conocido como ŌĆ£JONAS ŌĆō Just Online Navigation Analysis and Selection SystemŌĆØ (Sistema de An├Īlisis de Navegaci├│n y Selecci├│n Justo En L├Łnea).
La Historia se Repite
Posteriormente, en el 2014, fui contratado para un proyecto de consultor├Ła en otro ├ōrgano P├║blico del Estado de Brasil. En aquella ├®poca la Administraci├│n ten├Ła una gran expectativa en un proyecto, que llevaba como dos a├▒os en desarrollo, denominado ŌĆ£DWŌĆØ, el cual consist├Ła en el desarrollo de un banco de datos confiable residente en un servidor en la parte del ambiente operacional. Los datos eran transportados diariamente a este ambiente en un sistema basado en ACL (Audit Command Language) – Lenguaje de Comando de Auditor├Ła que ejecutaba los procedimientos de recuperaci├│n en ŌĆ£BatchŌĆØ (Lotes).
Aunque nuestro proyecto brind├│ alg├║n apoyo a la consecuci├│n del proyecto DW, luego de m├Īs de tres a├▒os el proyecto DW fue declarado inviable. O sea, transcurridos 5 a├▒os, la expectativa de tener una base de datos para recuperar informaci├│n esencial para la Administraci├│n se vio frustrada.
Pensando en una soluci├│n de transici├│n hasta tanto se tuviese el nuevo sistema y un DW que sirviese a la Administraci├│n, recuper├® el sistema JONAS descrito anteriormente que estaba en plataformas ya no apoyadas (Windows XP y Delphi 5), el cual fue instalado en una m├Īquina virtual, la cual podr├Ła ser una alternativa en el camino hacia una soluci├│n para atender las necesidades de informaci├│n de la Administraci├│n.
El JONAS fue configurado sobre la Base de Datos Operacional que serv├Ła a la Administraci├│n y no requiri├│ ning├║n ajuste para la presentaci├│n del prototipo como propuesta de un camino alterno. Desafortunadamente, nuestro proyecto no ten├Ła plazos ni recursos para desarrollar la soluci├│n en las plataformas actuales, lo que acab├│ ocurriendo posteriormente con la construcci├│n del JONAS 2.0 utilizando otros recursos.
La soluci├│n descrita es muy adecuada para la recuperaci├│n de informaci├│n con car├Īcter sistem├Ītico o transitorio en espera o no de otras soluciones. Su capacidad de informaci├│n es algo impresionante. Veamos a t├Łtulo de ejercicio el siguiente ejemplo:
Suponiendo que hay 20 Temas, cada uno con 5 atributos recuperables de informaci├│n (una dimensi├│n, por ejemplo, el Municipio es ├║nico independientemente de los valores posibles) podemos hacer el siguiente estimado:
Ante todo, 20 x 5 = 100 atributos. Del an├Īlisis combinatorio:
| C 100,1 | = | 100! / (1! * 99!) | = | 100 |
| C 100,2 | = | 100! / (2! * 98!) = 100 * 99 / 2 | = | 4.950 |
| C 100,3 | = | 100! / (3! * 97!) = 100 * 99 * 98 / 6 | = | 161.700 |
O sea: Existen 166,750 opciones de combinaci├│n de hasta 3 atributos, si fueran m├Īs atributos …
Obviamente muchas de las combinaciones podr├Łan no tener sentido, pero est├Īn disponibles para los entendidos. Podemos decir que: En la profundidad de los datos no procesados existe una riqueza de informaciones que espera ser resaltada.
 Vista de interfase con el Hist├│rico de Investigaciones
Vista de interfase con el Hist├│rico de Investigaciones
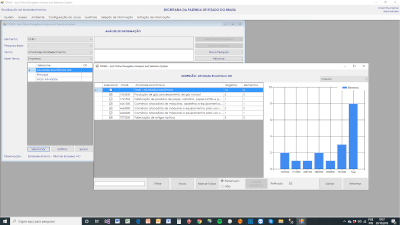 Vista del An├Īlisis de Informaci├│n seleccionando la Dimensi├│n Actividad Econ├│mica
Vista del An├Īlisis de Informaci├│n seleccionando la Dimensi├│n Actividad Econ├│mica
4,300 total views, 2 views today