Procesamiento de lenguaje natural en la detección de fraudes en facturas del municipio de Sao Paulo (parte 1)

1. Introducción
La Inteligencia Artificial (IA) se ha explorado para resolver problemas en diversas áreas del conocimiento. En el ámbito de la Administración Pública, la IA puede proporcionar automatización y eficiencia en tareas rutinarias en la planificación y en el ahorro de recursos (Souza et al. 2022). Las administraciones tributarias se enfrentan a desafíos. Para cumplir con sus misiones institucionales, la AT puede aplicar IA para mejorar las auditorías fiscales (Nunes; Delgado 2023).
La motivación del uso de la IA es perceptible en el cotidiano de trabajo de la Administración Tributaria de la prefectura de Sao Paulo. En el sector de fiscalización, el análisis de facturas de servicios electrónicos (NFS-e) permite constatar comportamientos de ciertos contribuyentes. Al cumplimentar el desglose de servicios en la NFS-e, utilizan textos que describen servicios gravados al 5%, pero aplican códigos de servicios que tienen un tipo inferior, lo que da lugar a un pago insuficiente.
Tenga en cuenta también el gran volumen de facturas y contribuyentes. Analizando el territorio brasileño, las estadísticas apuntan a la emisión de 40.394 mil millones de facturas desde 2006 para un total de 226.5 millones de contribuyentes (Receita Federal do Brasil 2024). En el municipio de Sao Paulo, datos de la Secretaría de Finanzas Municipales registran para el año 2023, 664.215.745 facturas emitidas por un total de 825.013 contribuyentes. El análisis manual de ese volumen es costoso, y la tendencia es que los contribuyentes se valgan de esa dificultad para defraudar las NFS-e de la forma anteriormente explicada. Los conjuntos de datos como el descrito son difíciles de procesar y se consideran un problema de Big Data (SAS 2024a). Este contexto demanda análisis automatizados que posibilitan decisiones más rápidas y programaciones fiscales asertivas, apalancando ingresos tributarios.
De esta forma, se utiliza la técnica de la IA y de Big Data. El procesamiento del lenguaje natural (PLN) proporciona un marco de técnicas para el análisis de textos (Jurafsky; Martin 2008). Así, el objetivo de este trabajo es aplicar el PLN buscando descubrir cuáles son los términos más frecuentes usados en discriminaciones de servicios de alícuotas mayores pero que están siendo utilizados en notas con código de servicio de alícuota menor.
Se han desarrollado trabajos relacionados con la aplicación del PLN en la detección de fraudes en facturas. Marinho (2023) hizo un estudio con 10.000 facturas del Distrito Federal. Se han calculado similitudes entre el texto descriptivo del producto en la nota y la nomenclatura oficial de la mercancía por el Mercosur. Las facturas fiscales se consideraron inconsistentes para las similitudes bajas, lo que ayudó al análisis de los auditores. Darrazon et al. (2023) basaron su estudio en un conjunto de facturas de do Piauí. En el trabajo, partiendo de un rol de 1.000.506 notas, fueron seleccionadas aleatoriamente 200 que fueron categorizadas manualmente. Se aplicaron algoritmos de clasificación y se evaluaron los resultados. Santos (2022) desarrolló un trabajo para clasificar textos descriptivos de facturas. La base de datos utilizada de 30.000 facturas fue proporcionada por el Ministerio Público de Paraíba. Una muestra de los datos se clasificó manualmente. Se aplicaron técnicas de PLN para clasificar las notas.
Las soluciones del estado del arte dependen del trabajo manual y usan conjuntos de datos de representatividad reducida en relación con el volumen de facturas contemporáneamente existente. Además, no se han encontrado estudios cuyo objetivo sea detectar el fraude en el uso indebido de los tipos impositivos y que contemplen el análisis de los términos más frecuentes en los desgloses de los servicios.
2. Referencial teórico
En esta sección se explican los conceptos relacionados con Hadoop y PLN
2.1 Hadoop
Hadoop (Apache Hadoop 2006) es un sistema que extrae, almacena y analiza grandes volúmenes de datos (SAS 2024b). Según la Figura 1, la arquitectura de Hadoop está formada por una red de computadoras que distribuye el almacenamiento y el procesamiento de datos (Machado 2017).
Figura 1 – Arquitectura de Hadoop
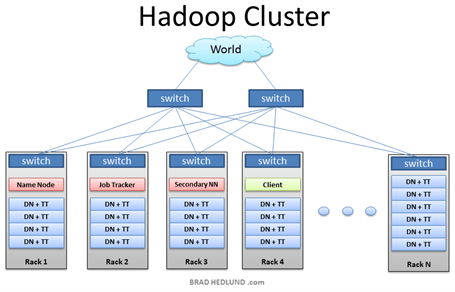
Fuente: Machado (2017).
Es posible acoplar al sistema Hadoop el componente Spark según la Figura 2, que complementa el sistema con funciones de streaming y de IA (Techvidvan 2024).
Figura 2 – integración entre Hadoop y Spark
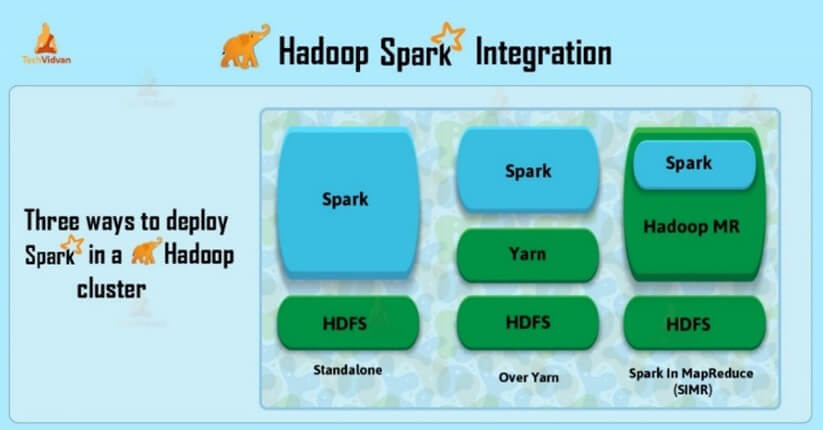
Fuente: Techvidvan (2024).
2.2 Procesamiento del lenguaje natural
El PLN (Jurafsky; Martin 2008) permite a las computadoras realizar tareas que involucran el lenguaje humano y se aplica a áreas como el reconocimiento de voz y el análisis semántico (Steedman 1996).
2.2.1 Preprocesamiento de texto
La primera técnica que se utiliza en PLN es la tokenización, que divide un texto en unidades, pudiendo estas ser palabras o números (Manning; Schütze 1999). Una vez que el texto está tokenizado, se aplican técnicas de reducción de palabras como la radicalización y lematización. En la primera se eliminan prefijos y sufijos. En la segunda se reduce una palabra a su lema: por ejemplo, la palabra ‘amigos’ se convierte en ‘amigo’. Se eliminan palabras que no tengan utilidad, como artículos y preposiciones, denominadas palabras clave.
2.2.2 Representación vectorial
Se utiliza el modelo bag of words, que crea un vector con una dimensión dada por la cantidad de palabras diferentes, almacenando en cada espacio del vector la frecuencia de la palabra respectiva (Feldman; Sanger 2006). Algunos modelos se basan en la concurrencia de palabras, utilizando una matriz donde cada fila es una palabra y las columnas los documentos, siendo la celda de la matriz la frecuencia de la palabra por documento (Jurafsky; Martin 2008).
El modelo de la frecuencia del término-inverso de la frecuencia en documentos, en inglés Term Frequency-Inverse Document Frequency (TF-IDF), se basa en la co-ocurrencia de palabras. TF calcula la frecuencia con la que aparece un término t dado en un documento d y las IDF ponderan la cantidad total de documentos y la cantidad de documentos en los que aparece el término. El IDF está dado por:

Referencias
11,718 total views, 3 views today
3 comentarios
Excelente artículo, muy completo y actualizado , mis felicitaciones.
Desde México nuestro reconocimiento a este gran trabajo.
Las prácticas de facturación no son ajenas a ninguna Administración Tributaria del que sea.
Muy interesante los avances de la fiscalización con la ayuda de las TI, muy buen artículo.