Navegando nos Dados “In Natura”

No ano 2000 fui contratado para consultoria em Órgão Público de Estado no Brasil com a missão de desenvolver produtos para a Área de Fiscalização.
Àquela época uma empresa de grande porte da área de software estava desenvolvendo há mais de dois anos um Data Warehouse para atender ao Departamento de Fiscalização e não se vislumbrava quaisquer resultados dentro dos limites de tempo do projeto.
Ao analisar a documentação gerada, constatamos que esta era apenas uma documentação de intenções seguindo os padrões da metodologia da empresa e que refletia uma especificação feita pelos usuários, carecendo, pois de maiores detalhes técnicos necessários à consecução do projeto.
Dada a premência de resultados, partimos então para outra abordagem considerando as seguintes premissas quanto aos dados necessários ao projeto:
Quanto aos requerimentos necessários ao atendimento da área consideramos que:
Propusemos então a seguinte solução:
O sistema atua com refinamentos sucessivos: Uma pesquisa é composta de Elementos, resultado de seleções de atributos de um Tema. A inclusão de novos atributos gera um novo conjunto contido no conjunto inicial, e assim sucessivamente. Em qualquer momento a pesquisa pode ser salva, por já ser o resultado final, ou para uso em outras pesquisas, seja para recuperação e apresentação dos dados.
A esta altura alguns leitores devem estar preocupados com a proposta de acesso aos dados operacionais. A ideia é usar as mesmas estruturas, porem no caso em analise, usou-se sim dos mesmos dados operacionais, devido ao número limitado de usuários que acessam o sistema e principalmente por uma implementação do sistema conhecida como Conjunto Base. O Conjunto Base é um conjunto usado como referencia, de partida, ou seja, qualquer conjunto resultado sempre pertence ou está contido no Conjunto Base.
Entrar em um Tema como Arrecadação, Notas Fiscais Eletrônicas, entre outros sem um Conjunto Base pode ser demorado para um sistema que se propõe iterativo. Porem, se o Conjunto Base tem alguns milhares de Elementos e o banco de dados estiver bem configurado não há maiores problemas.
Exemplificando:
Consideramos a existência do Tema Cadastro, o Tema Atividades Econômicas dos Contribuintes, o Tema Arrecadação e o Tema Importações:
O objetivo é a obtenção dos Contribuintes identificados por CNPJ de uma faixa de capital social, de um conjunto de Atividades Econômicas e que importaram mais de um determinado valor e pagaram menos do que um valor de imposto em um período de referencia dado;
Em 4 temos o resultado desejado, uma lista de CNPJ que atende ao exemplo. O usuário poderia efetuar quaisquer das outras operações nos conjuntos obtendo os conjuntos conforme a sua necessidade, ou mesmo seguir outra estratégia de navegação. Ademais se a quantidade de elementos não atende aos requisitos, o usuário pode ajustar o capital social ou usar outros códigos de atividade econômica, ou utilizar outros parâmetros para incluir ou eliminar contribuintes do conjunto selecionado.
Uma vez obtido o conjunto de elementos adequado, salvo em um histórico de pesquisas, este conjunto pode ser utilizado a qualquer momento para a extração dos dados de quaisquer Temas configurados no sistema, ou servir de controle para a geração de casos e emissão das ordens de serviço para as equipes de fiscalização, ou servir de conjuntos a participar de outras operações com novos conjuntos.
Este sistema ficou disponível na sua versão inicial em 6 meses e o resultado foi tão satisfatório que passou a ser usado pela Assessoria do Secretário da Receita para extração de informação gerencial da área de arrecadação entre outras.
Na versão inicial implantada este sistema era conhecido como “PLAFIS –Planejamento da Fiscalização – Módulo Gerencial”. Posteriormente, ficou conhecido como “JONAS – Just Online Navigation Analisis and Selection System”.
A História se Repete
Posteriormente, em 2014, em fui contratado em projeto de consultoria a outro Órgão Público de Estado no Brasil. Àquela época a Administração tinha uma grande expectativa em um projeto, já com dois anos de desenvolvimento, denominado “DW” que era a construção de um banco de dados confiável residente em um servidor à parte do ambiente operacional. Os dados eram diariamente transportados a este ambiente e um sistema baseado em ACL (Audit Command Language) executava os procedimentos de recuperação em “Batch” (Lotes).
Embora o nosso projeto tenha dado algum apoio à consecução do projeto DW, ao final de mais três anos o projeto DW foi declarado inviável. Ou seja, passados 5 anos, a expectativa de ter uma base de dados para recuperar informação essencial à Administração foi frustrada.
Pensando em uma solução de transição enquanto não se tivesse o novo sistema e um DW que atendesse a Administração, recuperei o sistema JONAS descrito acima que estava em plataformas não mais suportadas (Windows XP e Delphi 5), que foi instalado em uma máquina virtual, mas que poderia ser uma alternativa no encaminhamento de uma solução para atender as necessidades de informação da Administração.
O JONAS foi configurado sobre Banco de Dados Operacional que atendia a Administração e não necessitou de nenhum ajuste para a apresentação do protótipo como proposta de um caminho alternativo. Infelizmente o nosso projeto não possuía prazos nem recursos para o desenvolvimento de solução nas plataformas atuais, o que acabou ocorrendo posteriormente com a construção do JONAS 2.0 utilizando outros recursos.
A solução descrita é uma solução muito adequada para a recuperação de informação em caráter sistemático ou transitório no aguardo ou não de outras soluções. Sua capacidade de informação é algo impressionante. Vejamos a título de exercício o seguinte exemplo:
Supondo haver 20 Temas, cada um com 5 atributos recuperáveis de informação (uma dimensão, por exemplo, Município é único independente dos valores possíveis) podemos fazer a seguinte estimativa:
Ao todo 20 x 5 = 100 atributos. Da análise combinatória:
| C 100,1 | = | 100! / (1! * 99!) | = | 100 |
| C 100,2 | = | 100! / (2! * 98!) = 100 * 99 / 2 | = | 4.950 |
| C 100,3 | = | 100! / (3! * 97!) = 100 * 99 * 98 / 6 | = | 161.700 |
Ou seja: Existem 166.750 opções de combinação até 3 atributos, se forem mais atributos.
Obviamente muitas das combinações podem não fazer sentido, mas estão disponíveis para os curiosos. Podemos dizer que: Nas profundezas dos dados brutos existe uma riqueza de informações no aguardo em ser alçada.
 Vista da interface com Histórico de Pesquisas
Vista da interface com Histórico de Pesquisas
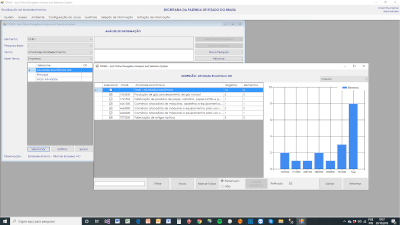 Vista da Analise de Informação selecionando a Dimensão Atividade Econômica
Vista da Analise de Informação selecionando a Dimensão Atividade Econômica
3,879 total views, 1 views today